Data import
General settings
| Setting | Description |
|---|---|
| Name | Type a unique name for the system. Two systems cannot have the same name. |
| System ID | Type a unique System ID for the system. Two systems cannot have the same System ID. You cannot change this setting. |
| Description | Type an optional description of the system. |
| Status | Status of the system. Set the status to Removed to ensure the system is no longer included in warehouse imports, reconciliation or provisioning. Setting a system as removed will delete all objects referring to the system, including resources, manual and automated provisioning tasks, and assignment policies. |
| Content | The type of content to import. You can choose: Identity data Access rights Both (Identity data and access rights). |
| Trusts | Optionally, select one or more trusted systems to associate with the system. |
Trust is specifically designed for use between physical systems. It is not intended for use between logical (software) and physical (hardware) systems.
Connection details
| Parameter | Description |
|---|---|
| Base URL | This field is optional.You can specify the Base URL of the service. When you specify a Base URL, this URL will be used for all defined queries if these do not specify a full URL of their own. The Base URL is part of the data connection data, and the Base URL should not be transported between environments, for example, http://company.com/odata/v2 |
| Authentication type | Choose the type of authentication to use for the REST system. The available options are: API Key – uses API Key keywords AWS Signature – adds authentication information to the HTTP header of Amazon Web Services requests. Basic – uses Base64-encoded string that contains a username and password. Negotiate – automatically selects between NTLM and Kerberos, depending on availability. NTLM – NT LAN Manager authentication uses Windows credentials to transform the challenge data. Digest – a challenge-response authentication that uses a nonce which is a string of random data. Kerberos – uses a ticket granting system for authenticating users. OAuth 2.0 SAML – uses SAML 2.0 protocol OAuth2 Client Credentials – uses an access token. OAuth2 Custom - the authentication server provides the token required for the authentication request. JSONPath expressions are supported, enabling the token retrieval from nested JSON objects (example: { "tokenInfo" : { "tokenValue" : "12345" } } - in this case, you can set the Access Token Location to $.tokenInfo.tokenValue). OAuth2 Password – uses user’s credentials to acquire access token. OAuth2 JWT – uses JSON web token. OAuth2 Client Credentials Using Basic Authentication - uses SAP Username and password. Depending on the type of authentication that you choose to use with the system, you may see more or fewer settings appear in the dialog box. |
| User | Enter the user name for the user to authenticate with the service. |
| Password | Enter the password for the user to authenticate with the service. Each time you make a change to any of the settings in the Connection details dialog box, you must provide your password again. |
| Domain | This field is optional. You can specify the domain name for the user. |
| Headers | This field is optional. You can provide JSON document specifying custom headers, for example, {"Request": {"Accept": " text/html","content-type": "application/json","SomeCustomHeaderWithValue": "custom value", "SomeCustomHeaderWithoutValue": null}} |
| Include certificate | If selected, a client certificate will be attached to the HTTP requests. Three additional parameters are required: - Certificate (in the PEM format) -----BEGIN CERTIFICATE----- <contents> -----END CERTIFICATE----- - Private Key (in the PEM format) -----BEGIN PRIVATE KEY----- .... -----END PRIVATE KEY----- - Passphrase for private key (optional, use it if the private key was created with the passphrase ) |
| API Key | This field applies only to API Key authentication option. Define the API Key keyword, for example, for DataDog environment: DD-API-KEY. |
| API Key Value | This field applies only to API Keyauthentication option. Define the API Key value, for example, for DataDog environment: … |
| Application Key | This field applies only to API Key authentication option. Define the associated Application Key keyword, for example, for DataDog environment: DD-APPLICATION-KEY. |
| Application Key Value | This field applies only to API Key authentication option. Define the associated Application Key value, for example, for DataDog environment … |
| Auth request body | This field applies only to OAuth2 Custom authentication option. Raw body of the request sent to authentication server to get the access token. Sensitive values should be replaced with the placeholders starting with #SECURE. |
| Auth request content type | This field applies only to OAuth2 Custom authentication option. Content type of the request sent to authentication server to get the access token. |
| Authentication server response format | This field applies only to OAuth2 Custom authentication option. The available options are: - Access token only - JSON - Other - XML |
| Access token Location | Required field for OAuth2 Custom if the Authentication server response format setting has value other than Access token only configured. Location of the access token in the response. Depending on the format, different kind of information is expected in this field: - property name if it is JSON - XPath if it is XML - regular expression with group if it is other, unknown format |
| Authorization header | This field applies only to OAuth2 Custom authentication option. Name of the authorization header, where access token will be stored. |
| SAML IDP Endpoint | This field applies only to OAuth 2.0 SAMLauthentication option. Enter the URL where SAML requests are posted. |
| Token endpoint | This field applies only to OAuth2 authentication options. Enter the URL used to exchange an authorization grant for an access token. |
| Client ID | This field applies only to OAuth2 authentication options. Enter the client identifier issued to the client during the registration process in the service. This identifier is used to authenticate at the Token endpoint. |
| Client secret | This field applies only to OAuth2 authentication options. Enter the generated secret for the Client ID. |
| Audience | This field applies only to OAuth2 Client Credentials authentication option. Enter the audience for your API token. |
| User ID | This field applies only to OAuth 2.0 SAMLauthentication options. Enter the user identifier issued to the user during the registration process in the service. |
| Company ID | This field applies only to OAuth 2.0 SAMLauthentication options. Enter the company identifier issued to the company during the registration process in the service. |
| Scope | This field applies only to all OAuth 2 authentication options except OAuth2 Static Token. Provide the scope of the request. |
| Resource | This field is optional. Here, you can specify the Resource for which authorization will be granted. |
| JWT Encryption algorithm | This field applies only to OAuth2 JWT authentication options. Select the encryption algorithm used when signing the token, for example, RSASSA-PKCS1-v1_5 using SHA-256 (RS256) |
| JWT Type | This field applies only to OAuth2 JWT authentication options. Enter a JWT Type (Header parameter) |
| JWT Public key ID | This field applies only to OAuth2 JWT authentication options. Enter a public key ID for signing the JWT (Header parameter) |
| JWT Issuer | This field applies only to OAuth2 JWT authentication options. Enter a JWT Issuer claim. |
| JWT Subject | This field applies only to OAuth2 JWT authentication options. Enter a JWT Subject claim. |
| JWT Audience | This field applies only to OAuth2 JWT authentication options. Enter a JWT Audience claim. |
| JWT Expiration time | This field applies only to OAuth2 JWT authentication options. Set a JWT Expiration time. |
| JWT Additional claims | This field applies only to OAuth2 JWT authentication options. Enter a JWT Additional claims in the JSON format (for text type, value enclosed in double quotes). Legacy format is also supported: key1,value1;key2,value2;... |
| JWT Private key (PEM format) | This field applies only to OAuth2 JWT authentication options. Enter a JWT Private key is in the PEM format: -----BEGIN PRIVATE KEY----- .... -----END PRIVATE KEY----- or -----BEGINENCRYPTED PRIVATE KEY----- .... -----END ENCRYPTED PRIVATE KEY-----and then Passphrase for Private Key needs to be provided. |
| JWT Passphrase for private key | This field applies only to OAuth2 JWT authentication options. Enter a Passphrase for the providedPrivate key. |
| JWT Token Parameter | This field applies only to OAuth2 JWT authentication options. This setting stores the JWT token parameter name. |
| Username | This field applies only to OAuth2 SAP authentication option. Provide the SAP username for a SAP Cloud system like SAP Cloud Identity Authentication Service (IAS). |
| Password | This field applies only to OAuth2 SAP authentication option. Provide the SAP password for a SAP Cloud system like SAP Cloud Identity Authentication Service (IAS). |
| Service Name | This field is mandatory when choosingAWS Signature authentication. Enter the name of the AWS API service that the authentication request will be sent to. |
| Secret Key | This field is mandatory when choosing AWS Signature authentication. Enter your IAM user secret key to authenticate your requests. |
| Access Key | This field is mandatory when choosing AWS Signature authentication. Enter your IAM user access key to authenticate your requests. |
| Region | This field is optional and only applies to AWS Signature authentication. Enter the AWS region for the authentication request. For the IAM service, it is recommended that you leave the field empty. |
| OAuth static token | This field applies only to OAuth2 Static Tokenauthentication option. Enter a statically generated bearer token.The value will be encrypted upon storage. |
| OAuth token type | This field applies to OAuth2 Static Token, OAuth2 JWT, OAuth2 Custom authentication option. Provide a custom keyword that will be supplied in front of the static token, for example, SSWS for OKTA or AFAS for AFAS integration. If the field is left blank, the default Bearer value is used. |
| Test connection | This field is optional.You can check this field to force the collector to test the defined connection before moving forward. |
| Test query | This field only appears if the Test connection field is enabled.Here you can enter an optional test query used to verify the connection.The query must be relative to the base address, e.g., 'Users.' Entering a test query is important for a proper test for authentication methods which doesn't access the target system, e.g., basic authentication or static bearer token. |
Configuring thresholds
The Configure thresholds function allows you to set the amount of changes that cannot be exceeded, relevant to the last import. In the Configure import thresholds view, type a number (integer) in percentage for New objects, Modified objects, and Deleted objects to enable thresholds for the import of objects from this system. The value for each operation is by default set to 0, which means that no threshold calculations take place for the operations until you change the integer.
For all .NET-based collectors, thresholds are calculated in the following relation:
- If the system category is set to Identity data, the thresholds are calculated.
- If the system category is set to Access data, the thresholds are calculated.
- If the system category is set to Both, the thresholds only apply to Access data, that is, Accounts, Resources, and ResourceAssignments.
Queries and mappings
Settings related to the Queries and mappings are divided into the following tabs:
General
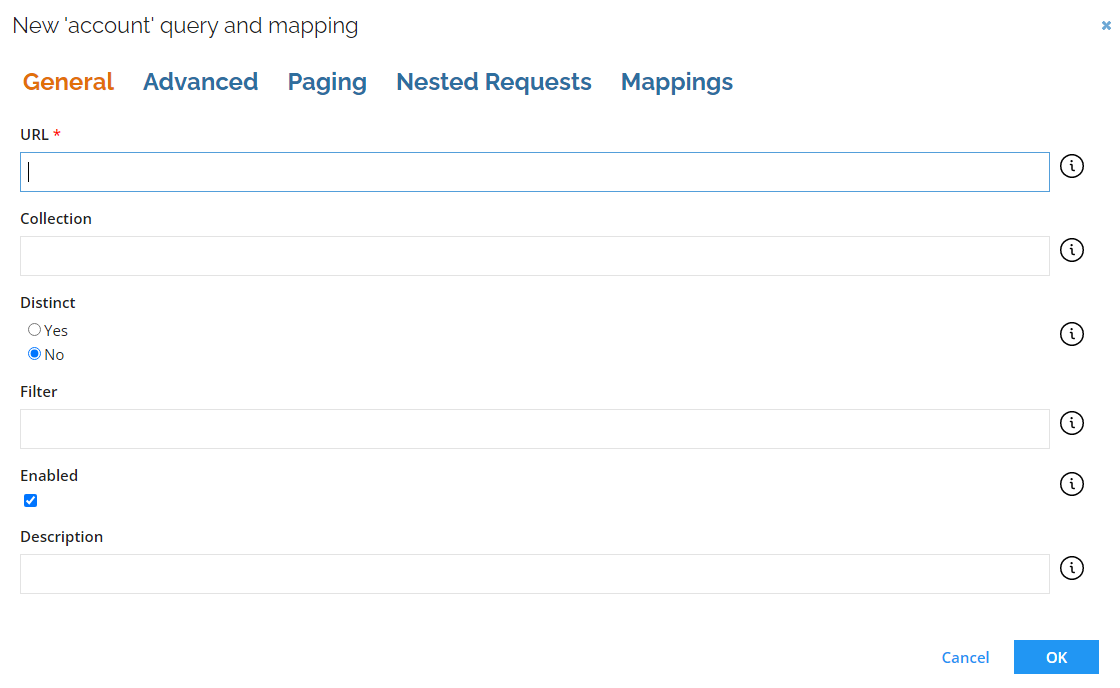
| Parameter | Description |
|---|---|
| URL | Here You can enter the URL for the resource. If No is selected in URL is a DynamicExpresso expression, you can specify a full URL or the part of the URL which should be appended to the Base URL. If Yes is selected in URL as a DynamicExpresso expression, the URL enables the user to specify a DynamicExpresso expression, which is used to generate the URL dynamically. |
| Collection | In the Collection field, you can specify the name of the collection element in the response from where the result should be read. By default, the result is read from the first found collection. |
| Distinct | In the Distinct field, specify if the collector should remove possible duplicate rows. |
| Filter | In the Filter field under the Parameters heading, you can provide a Dynamic Expresso expression that is used for filtering the data imported into Omada Identity. It returns a TRUE or FALSE result for each imported data row. If the expression returns FALSE for the given row that row is skipped during import. The filter can be supplied with special functions #MinRow() or #MaxRow(). The #MinRow()/#MaxRow() are custom functions that can be combined with regular DynamicExpresso expressions thanks to the # prefix. For example, in line: #MinRow(col1, col2)#col=="active" the custom function is encapsulated within the # at the start and optionally at the end if a regular filter is to be appended like in the example (col==\"active\"). The MinRow()/MaxRow() functions take two parameters. The intention is similar to a Group by function in SQL server that allows you to eliminate duplicates and to take the lowest or highest [order by column] for each [unique column] row, for example MinRow([unique column], [order by column]). |
MaxRow(UniqueKey, Version)
Input :
| UniqueKey | Version |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
| 2 | 1 |
| 3 | 1 |
Output :
| UniqueKey | Version |
|---|---|
| 1 | 2 |
| 2 | 2 |
| 3 | 1 |
| Parameter | Description |
|---|---|
| Enabled | Enables the imports within the provided settings. |
| Description | In the Description field, enter a description for what this query is doing. |
If the URL returns a collection (multivalue), the Nested URL will only be called using the first element of each collection.
Moreover, as the Nested URL is called for the number of rows returned from the URL, employing this feature causes a performance penalty.
The Nested URL field doesn't allow special characters.
Advanced
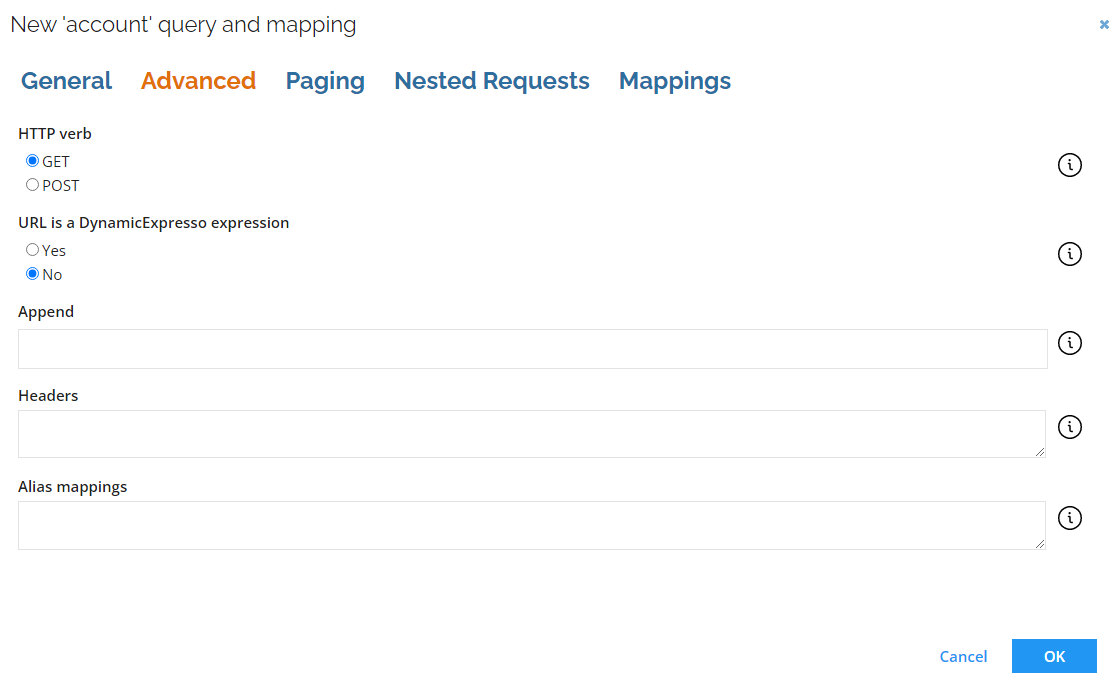
| Parameter | Description |
|---|---|
| HTTP verb | The HTTP Verb setting allows you to set the HTTP verb value different than GET. |
| Request body | The Request body setting, provides the body of the request. This setting should be configured only if the HTTP verb setting value is different than GET. The need to configure this setting should be based on the individual requirements of the API, since in most instances it is not necessary. |
| URL is a DynamicExpresso expression | You can specify whether the URL is generated from a DynamicExpresso expression (if Yes is selected) or interpreted directly (if No is selected). |
| Append | In the Append field, enter query parameters which should be appended. |
| Headers | In the Headers field you can specify headers on an query level. They are attached only to the requests for this specific query. |
| Alias mappings | The Alias mappings field allows to define aliases for JSON paths that can be later used for mappings. |
Paging
It is recommended to use the SuccessFactors paging mechanisms when querying PerPerson entity to avoid missing or duplicate records. This behavior occurs when the same Entity is updated by another process in parallel while being read from SAP. To enable the paging mechanism to add the paging=snapshot query parameter at the beginning
of the URL:
PerPerson?paging=snapshot&$filter...
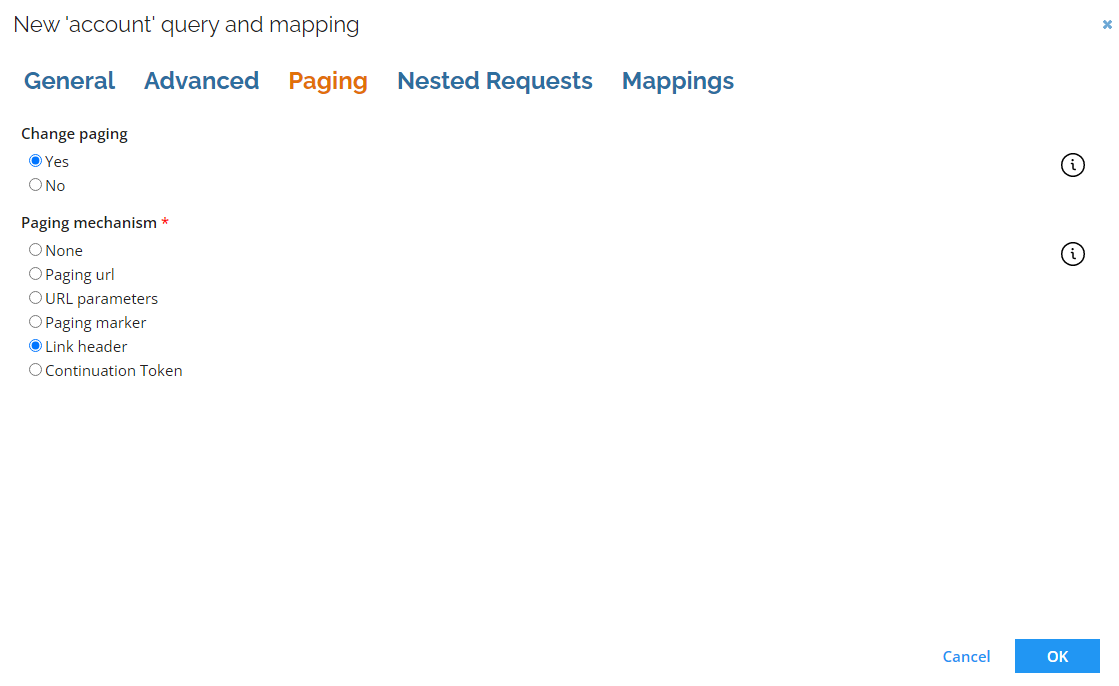
| Parameter | Description |
|---|---|
| Change paging | Defines whether paging should be adjusted on a query level. |
| Paging mechanism | Paging on a query level. Choose one of the following options: - None: No paging and all data is returned. - Paging URL: Use this option if the response contains a field with a URL for the next page. - URL parameters: Use this option if the paging must be specified as URL parameters. - Paging marker: Use this option if the response contains a field with an indicator which should be used in the URL for the subsequent call. If the response is truncated (that is, if it does not contain all the requested objects), it will contain an IsTruncated element set to True and a Marker element. The Marker value needs to be used as a parameter in the URL of the call for the subsequent page. - Link header: The collector verifies if the response contains a header link with rel="next", which points to the next page. This option doesn't require any additional configuration. - Continuation token: This option allows to utilize token provided in the response in the request for the next page. |
Nested Requests
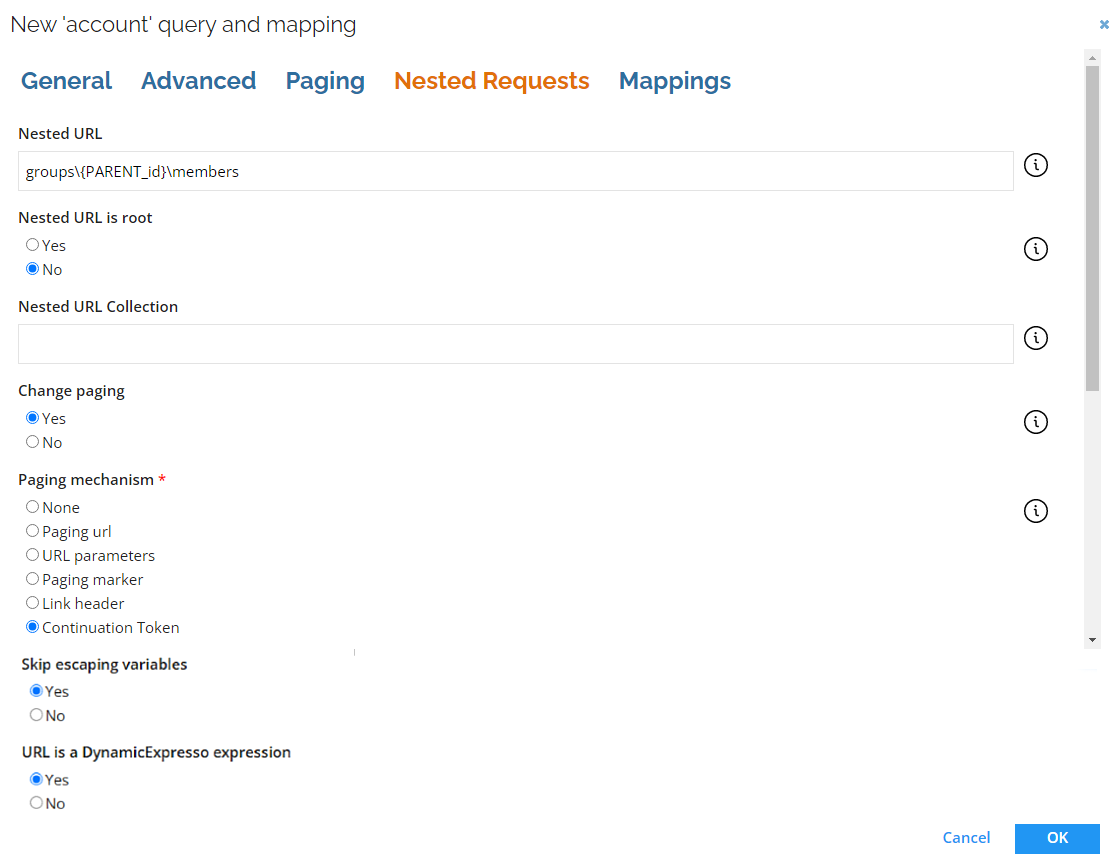
| Parameter | Description |
|---|---|
| Nested URL | In the Nested URL field, you can provide any attribute returned from the URL and use it as a nested query. The attribute must be enclosed in brackets, for example, /groups/{PARENT_id}/members?roles=MEMBER. Providing value in this field enables Nested URL. |
| Nested URL is root | In the Nested URL is a root radio button, you can specify whether the return should be the first found collection, by selecting No (which is the default value) or a root element treated as a single element, by selecting Yes. |
| Nested URL Collection | If the Nested URL is root parameter is set to Yes, then the Nested URL Collection must be specified as well, to point to the collection inside the root element from which you want to collect data. |
| Nested request body | The Nested request body setting, provides the body of the nested request. This setting should be configured only if the HTTP verb setting value is different than GET. Nested request body can utilize fields from the URL result, for example {\"user\":{PARENT_id}} . The need to configure this setting should be based on the individual requirements of the API, since in most instances it is not necessary. |
| Change paging | Using the Change paging setting you can decide if paging should be adjusted on an query level. |
| Paging mechanism | Select the type of paging on an query level. There are following options that can be selected: - None: Select this option if the service offers no paging and all data is returned. - Paging marker: Use this option if the response contains a field with an indicator which should be used in the URL for the subsequent call. If the response is truncated (that is, if it does not contain all the requested objects), it will contain an IsTruncated element set to True and a Marker element, which value needs to be used as a parameter in the URL of the call for the subsequent page. - Paging URL: Use this option if the response contains a field with a URL for the next page. - URL parameters: Use this option if the paging must be specified as URL parameters. - Link header: The collector verifies if the response contains header link with rel="next", which points to the next page. This option doesn't require any additional configuration. - Continuation token: This option allows to utilize token provided in the response in the request for the next page. |
| Skip escaping variables | Defines whether nested URL variables should be escaped (if set to true, nested URL variables are not escaped). |
| URL is a DynamicExpresso expression | Enable expressions to generate nested URLs dynamically. |
Mappings
Minimal required mappings
The Omada REST Connectivity requires the following mappings to be configured.
Accounts
| Destination | Description |
|---|---|
| Business key | The system’s key for the account. A unique value is required. |
| Unique ID | UID of the account. |
| Account name | Name of the account. |
Contexts
| Destination | Description |
|---|---|
| Business key | The system's key for the context. A unique value is required. |
| Name | Name of the context. |
| Type | Type of the context. |
Context assignments
| Destination | Description |
|---|---|
| Context business key | The system's key for the context. A unique value is required. |
| Identity UID | UID of the identity. |
Context owners
| Destination | Description |
|---|---|
| Context business key | The system's key for the context. A unique value is required. |
| Owner UID | UID of the context owner. |
Identities
| Destination | Description |
|---|---|
| Business key | The system's key for the identity. A unique value is required. |
| Unique ID | UID of the account. |
| Name | Name of the identity. |
| Status | Status of the identity. |
Importing Status from an HR system may overwrite important status change made in Enterprise Server (ES). To remedy the possible status change by the requirement of mapping the Status property in the collector mappings, we recommend disabling the mapping of this property within Warehouse to Portal mappings. Within ES, Status is maintained by the three standard events:
- Update identity status (terminated)
- Update identity status (active)
- Update identity status (inactive)
Identity Owners
| Destination | Description |
|---|---|
| Owner UID | UID of the identity owner. |
| Identity UID | UID of the identity. |
Resources
| Destination | Description |
|---|---|
| Business key | The system's key for the resource. A unique value is required. |
| Security resource business key | The system's key for the resource. |
| Name | Name of the resource. |
| Category | Category of the resource. |
| Type | Type of the resource. |
Resource assignments
| Destination | Description |
|---|---|
| Resource business key | The system's key for the resource. A unique value is required. |
| Account - business key | The business key for the account. |
| Account - CBK | The composed business key for the account. |
Resource owners
| Destination | Description |
|---|---|
| Resource business key | The system's key for the resource. A unique value is required. |
| Owner UID | UID of the resource owner. |
If you create a query to import resource owners, it is possible to specify the resource's owner in two ways. You can do it either by directly importing the UID of the identity or by specifying the account from which the resolved owner is imported as a resource owner.
When mapping directly to the UID of identity, ensure that identities are already imported to Omada Identity.
When mapping to an owned account, it is possible to either specify the business key of the account or the composed business key. The former should be used if the account is in the same system as the resource; the latter should be used if the account is imported into any of the trusted systems. When the account stems from another system, you should use a Lookup mapping.
Resource Parents / Children
| Destination | Description |
|---|---|
| Parent resource business key | The system's key for the parent resource. A unique value is required. |
| Child resource - business key | The system's key for the child resource. A unique value is required. |
| Child resource - CBK | The composed business key for the child resource. |
Alias mappings
The Alias mappings field allows to define aliases for JSON paths that can be later used for mappings.
Aliases 'mobile' and 'home' added

Aliases 'home' and 'mobile' used for setting mappings
The utilization of JSON paths allows to take advantage of their features. For example, you can selectively extract attribute from a node, as it was used in the above example to extract home and mobile phone numbers from the following JSON file sample:
[
{
"firstName": "John",
"lastName": "Doe",
"age": 16,
"address": {
"streetAddress": "Green",
"city": "Liverpool",
"postalCode": "L1 0BE"
},
"phoneNumbers": [
{
"type": "mobile",
"number": "123456789"
},
{
"type": "home",
"number": "987654321"
}
]
},
{
"firstName": "Jane",
"lastName": "Doe",
"age": 35,
"address": {
"streetAddress": "Yellow",
"city": "London",
"postalCode": "E1 6AN"
},
"phoneNumbers": [
{
"type": "mobile",
"number": "111222333"
},
{
"type": "home",
"number": "999888777"
}
]
}
]
Advanced configuration
-
You can select the Perform unfolding option to enable the system to unfold the parent-child hierarchy of the resource.
-
Optionally, in the Append URL parameters(s) field, enter any additional query parameters that should be added to any of the queries defined under Queries and Mappings.
noteThe value must be entered following standard of the service, for example,
parameter1=value¶meter2=value. The collector ensures correct formatting of the entire URL. -
Optionally, in the Security Protocol drop-down list, choose a security protocol to use for an HTTPS connection (TLS 1.2). Your organization may limit the use of one or more of the default available security protocols.
-
Optionally, in the Paging mechanism field, select the type of paging the service uses. Services may result from large datasets and will return data in chunks. The REST collector offers the following options:
- None: Select this option if the service offers no paging and all data is returned.
- Paging marker: Use this option if the response contains a field with an indicator which should be used in the URL for the subsequent call. If the response is truncated (that is, if it does not contain all the requested objects), it will contain an IsTruncated element set to True and a Marker element, whose value needs to be used as a parameter in the URL of the call for the subsequent page.
- Paging URL: Use this option if the response contains a field with a URL for the next page.
- URL parameters: Use this option if the paging must be specified as URL parameters.
- Link header: The collector verifies if the response contains header link with
rel="next", which points to the next page. This option doesn't require any additional configuration. - Continuation token: This option allows to utilize token provided in the response in the request for the next page.
- Paging marker
- Paging URL
- URL parameters
- Continuation token
-
In the Marker element field, type in the name of the response element, whose value will be used in the subsequent pagination requests to obtain the next set of items if the pagination results are truncated.
-
In the Marker parameter field, type in the name of the parameter that will be used in the subsequent pagination requests, with the Marker element value, to obtain the next set of items.
In the Paging URL field, specify the JSON field in the response that contains the URL for the next page of data. The collector will continue querying the service until this field is empty.
- In the URL Parameters field, enter the parameters that must be appended to the query to get the next page of data. If the parameter name is not provided the value is added to the URL routing.
You can use variables from the response by placing the name of the field in curly brackets. The following variables are supported:
- Index: Contains the index of the next record to be fetched, for example
startIndex={index}&count=100. - PageIndex: Contains the next page number to be fetched, for example,
page={pageIndex}&per_page=100.
-
Optionally, in the Total field, enter the JSON field in the response that indicates the total amount of records. If this field is not specified, the service will be called until an empty result set is returned.
-
The Timeout in seconds field allows you to specify how long the collector should wait for a response of the REST service. The default value is set to 3600 seconds (1 hour).
-
In the optional Row count per batch field you can set the number of objects that will be collected and staged as a batch when paging is implemented in the collector. The default value is 100000.
Applying a low value, for example 50 or 500, to this setting may result in extended import time.
- The Location of continuation token in the response setting allows to toggle, depending on the API, whether the continuation token is provided in the HTTP header or response body.
Only JSON body is supported.
-
The Name of the continuation token parameter in the response setting allows, depending on the location of the token, to provide name of the HTTP header or property in the body. If the location is body and continuation token is not available in the property of the root object, you can specify JSON path to the correct property.
-
The Location of continuation token in the request setting allows to specify where the continuation token should be attached in the request. Available options are HTTP header, URL parameter or body (this option is supported if the HTTP verb is set to value other than GET).
-
The Name of the continuation token parameter in the request setting allows, depending on location, to specify the name of the HTTP header, URL parameter or property in the body.
-
The Add to the URL for the request that includes a continuation token setting provides an additional path or parameter to add to the URL when a continuation token is provided in the request. If the value contains an equals sign, it is treated as a URL parameter, otherwise it is added as a URL path.