Introduction to Horizons
To see which components were updated and what new functionalities were added visit the Horizons Release Notes page.
The Horizons functionality is a new approach towards data ingestion, which is a crucial step in the data processing lifecycle. Its main goal is to integrate and consolidate data from dispersed sources into a unified, coherent centralized repository. Usually, it's performed in data-intensive and saturated environments, such as data warehouses, data lakes, and analytical systems.
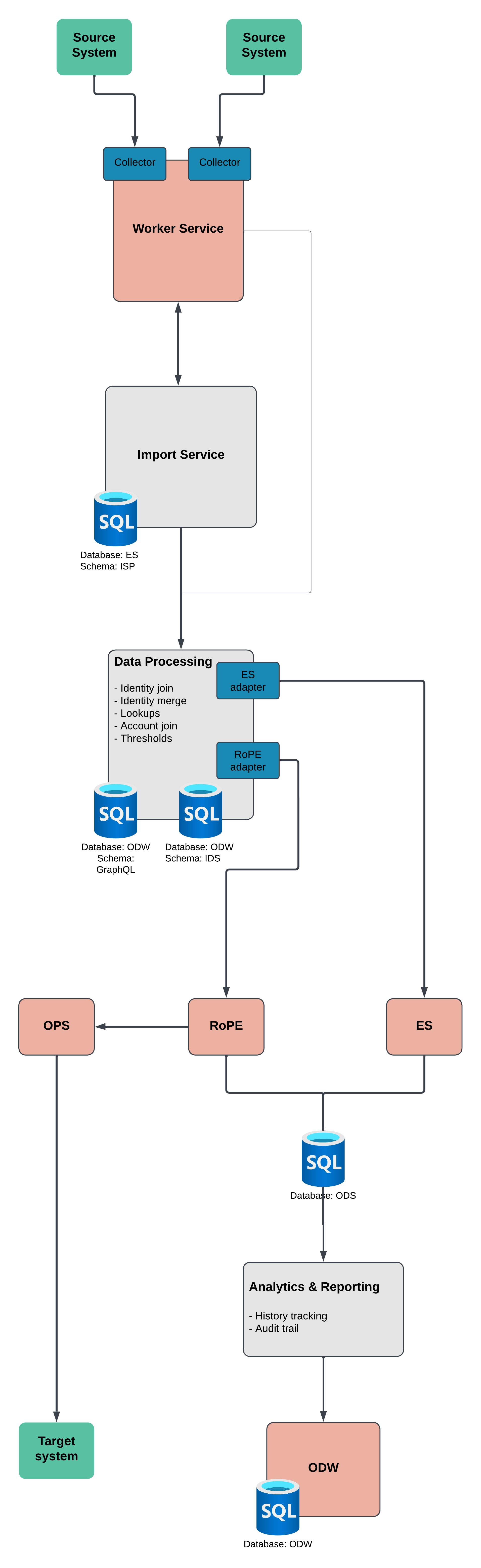
The process itself can be divided into three distinctive stages.

Staging
It is a phase in which the data from the source system is extracted and undergoes the data transformation configured in the queries and mappings for system onboarding.
The extracted data goes through transformation processes in a following order:
- Filtering
- Group filtering
- Dynamic expresso filtering
- Property mapping
- Row expanding
- Orphan filtering
- Distinct filtering
- XML encoding
Filtering
The data from the source system can undergo either group filtering or the dynamic expresso filtering.
- Group filtering
- Dynamic expresso filtering
The group filtering is applied when the Filter setting in the General tab in the Identity queries mapping is configured with either #MAXROW or #MINROW function.
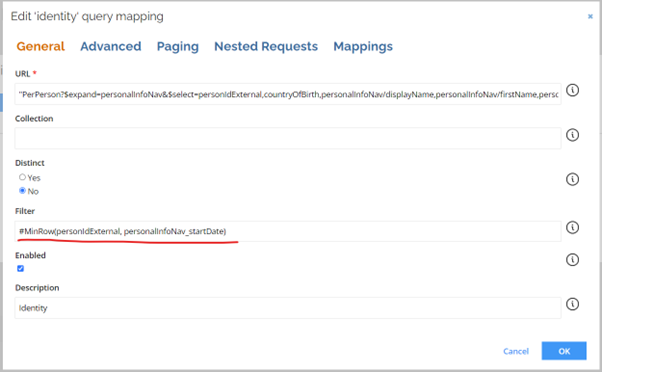
When group filtering is used, the data from the target system are processed in a single instant and only after that group filtering and other transformations are applied.
The group filtering utilizes more memory which impacts the overall performance.
The dynamic expresso filtering allows you to remove data from the query based on the specify expression, that is C# compliant.
Filtering is applied on the source data, hence the expression used in the filter must utilized naming from the source column.
The filtering is applied to all values assigned to a property in the data source. If all of the values for a given property are removed, the whole row is then removed.
Property mapping
During property mapping the source data, following the mappings set on the query, are adjusted to fit the entity model. If a property in the source data has multiple values, the mapping is applied to all of them.
Depending on your requirements you can transform a single value property into multiple values, by splitting a delimited string.
For a transformation from a multiple value property to a single value, you can merge those multiple values by using, for example, the string.Join() expression.
Row expanding
In the row expansion process, rows containing multiple values properties are split into separate rows.
A multiple value property below
{
"Resource_BusinessKey": [ "resource_one" ],
"Account_BusinessKey": [ "account_one", "account_two" ]
}
is separated into two rows
{
"Resource_BusinessKey": [ "resource_one" ],
"Account_BusinessKey": [ "account_one" ]
},
{
"Resource_BusinessKey": [ "resource_one" ],
"Account_BusinessKey": [ "account_two" ]
}
Each multiple value property must contain the same number of assigned value, otherwise an exception is thrown.
By default the extension attributes are not expanded with two exceptions present:
- The source value that is mapped to the extension attribute is also a source for a standard attribute.
- The source value mapped to the extension attribute is also a part of the source object mapped to a standard attribute.
Examples of row expanding
Source value mapped to extension and standard attribute
The following snippet from a source system
[
{
"Id": [ "resource_one ],
"Member_Id": [ "account_one", "account_two" ]
}
]
that has the corresponding mappings
<query type="resourceassignment">
<map dest="Resource_BusinessKey">Id</map>
<map dest="Account_BusinessKey">Member_Id</map>
<map dest="EXTENSIONATTRIBUTESwithoutHISTORY" extAttrName="account" multiValued="false" >Member_Id</map>
</query>
indicates that the Member_Id is a source for an extension attribute and standard Account_BusinessKey as well. This results in the expansion of the row in the following way:
[
{
"Resource_BusinessKey": [ "resource_one" ],
"Account_BusinessKey": [ "account_one" ],
"EXTENSIONATTRIBUTESWITHOUTHISTORY_account": [ "account_one" ]
},
{
"Resource_BusinessKey": [ "resource_one" ],
"Account_BusinessKey": [ "account_two" ],
"EXTENSIONATTRIBUTESWITHOUTHISTORY_account": [ "account_two" ]
}
]
Source value mapped to extension attribute is a part of source object mapped to a standard attribute
The following snippet from a source system
[
{
"Id": [ "resource_one ],
"Member_Id": [ "account_one", "account_two" ],
"Member_Role": [ "read", "write" ]
}
]
that has the corresponding mappings
<query type="resourceassignment">
<map dest="Resource_BusinessKey">Id</map>
<map dest="Account_BusinessKey">Member_Id</map>
<map dest="EXTENSIONATTRIBUTESwithoutHISTORY" extAttrName="role" multiValued="true" >Member_Id</map>
</query>
indicates that the Member_Role originates from the same source object as Member_Id, which is mapped to a standard attribute. This results in the expansion of the row in the following way:
[
{
"Resource_BusinessKey": [ "resource_one" ],
"Account_BusinessKey": [ "account_one" ],
"EXTENSIONATTRIBUTESWITHOUTHISTORY_role": [ "read" ]
},
{
"Resource_BusinessKey": [ "resource_one" ],
"Account_BusinessKey": [ "account_two" ],
"EXTENSIONATTRIBUTESWITHOUTHISTORY_role": [ "write" ]
}
]
The source object is determined by its placement before the last underscore. For example for Member_Id the Member is the the source object. Similarly, for the Member_Role_Types the Member_Role is the source object.
Orphan filtering
In this process, after the transformation and expansion, rows with any of the key properties values equal to null are removed.
For more information on key properties, go to Key properties section.
Distinct filtering
The distinct filtering is applied, when configured on a query, to detect duplicates of the key properties. Rows with duplicated combination of the key properties are then ignored. If a BusinessKey property is mapped to a relational object, for example resource assignments, only the BusinessKey property is verified with the distinct filter overlooking other key properties.
The import and transformation of data utilizes parallel processing and the order in which rows are filtered out can't be guaranteed.
For more information on key properties, go to Key properties section.
XML coding
In this process the XML tags present in the BusinessKey value are encoded. Encoding can be disabled in the system configuration allowing to omit this transformation.
Additional information
Key properties
Depending on the entity types there are different sets of key properties.
| Entity type | Key properties |
|---|---|
| Account | BusinessKey |
| Context | BusinessKey |
| Context assignments | Context_BusinessKey IdentityUID |
| Context owner | Context_BusinessKey OwnerUID |
| Identity | BusinessKey |
| Identity owner | IdentityUID OwnerUID |
| Resource | BusinessKey |
| Resource assignment | Resource_BusinessKey Account_BusinessKey or Account_ComposedBusinessKey |
| Resource owner | Resource_BusinessKey OwnerUID or Account_BusinessKey or Account_ComposedBusinessKey |
| Resource parent-child | Resource_BusinessKey Child_BusinessKey or Child_ComposedBusinessKey |
Transformation statistics
There is an array of statistics and data gathered during an import. You can access them from import logs or log analytics.
Accessing import statistics
-
Go to logs and set the filtering in the Message column to Entity statistics
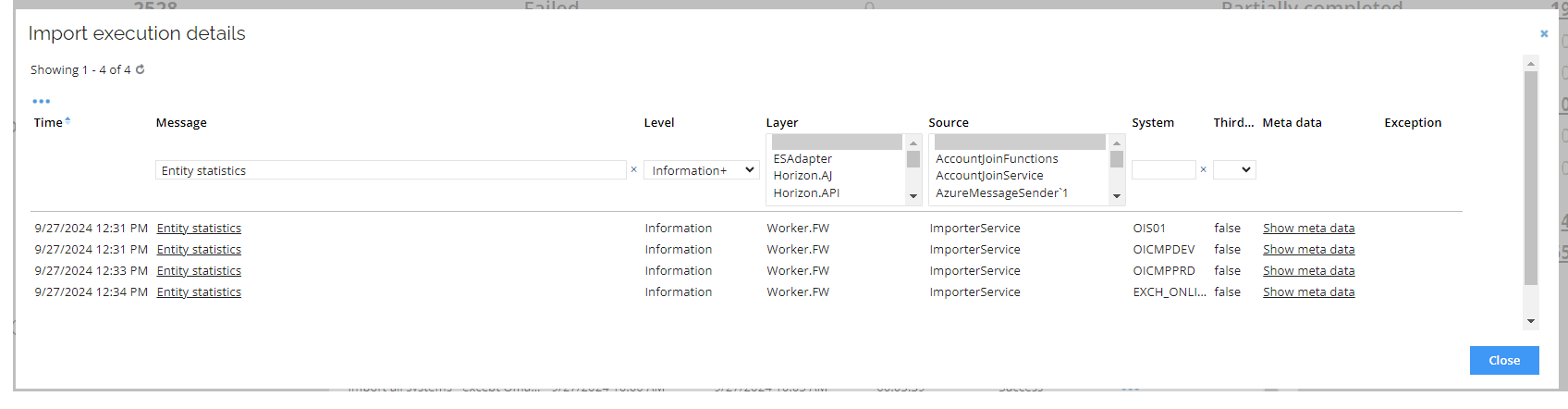
Each system participating in the import has a separate entry in the log. You can identify the system by referncing the value in the System column.
-
To access detailed information click the Show meta data link in the Meta data column.
For each entity the statistics are shared in a JSON format.
We are going to use a snippet of import statistics for the resource assignments
{
"Statistics-Entity_ResourceAssignments": {
"Collector": 907,
"Transformer#1-CustomRowFilter":907,
"Transformer#2-RowFilter": 907,
"Transformer#3-SourceMappingsAnalyzer": 907,
"Transformer#4-PropertyMapper": 907,
"Transformer#5-MultiRowExpander": 907,
"Transformer#6-KeyValueTrimmer": 2262,
"Transformer#7-OrphanFilter": 2262,
"Transformer#8-DistinctFilter": 2216,
"Transformer#9-ReplaceXmlTags": 2216,
"Receiver-IngestionApiReceiver": 2216,
"Queries": ...
}
}
In the root node you can find accumulated data over all queries for a selected entity type. The Collector node informs you how many rows were returned by the collector across the target system pages. The Receiver-IngestionApiReceiver node indicates how many rows, after transformation, are forwarded to processing stage.
In the same way to can establish how many rows were received by the transformer from the previous step.
To access statistics for a specific query, expand the Queries node. It is a good practice to provide a description for a query, making it easier to find.
{
"Statistics-Entity_ResourceAssignments": {
"Collector": 907,
"Transformer#1-CustomRowFilter":907,
"Transformer#2-RowFilter": 907,
"Transformer#3-SourceMappingsAnalyzer": 907,
"Transformer#4-PropertyMapper": 907,
"Transformer#5-MultiRowExpander": 907,
"Transformer#6-KeyValueTrimmer": 2262,
"Transformer#7-OrphanFilter": 2262,
"Transformer#8-DistinctFilter": 2216,
"Transformer#9-ReplaceXmlTags": 2216,
"Receiver-IngestionApiReceiver": 2216,
"Queries": [
{
"QueryId": "0A111F19A065F6D0B56B5F550EE122B13EEFDC9AC6A97A9E2FCC120731AADF99",
"Description": null,
"Collector": 446,
"Transformer#1-CustomRowFilter":446,
"Transformer#2-RowFilter": 446,
"Transformer#3-SourceMappingsAnalyzer": 446,
"Transformer#4-PropertyMapper": 446,
"Transformer#5-MultiRowExpander": 446,
"Transformer#6-KeyValueTrimmer": 446,
"Transformer#7-OrphanFilter": 446,
"Transformer#8-DistinctFilter": 446,
"Transformer#9-ReplaceXmlTags": 446,
"Receiver-IngestionApiReceiver": 446
},
... ,
...
]
}
}
Processing
In this stage the data is forwarded to Internal Data Store (IDS) for processing in accordance with configuration in Enterprise Server. The data undergoes following steps:
- Thresholds - The incoming data is compared against a configured threshold for created, changed, or deleted objects detected during import. Exceeding the threshold halts further processing.
- Identity Join - Corresponding identity records incoming from multiple sources are merged into a single, unique record.
- Identity Merge - Properties from multiple source systems, related to the same entity, are merged and allocated to a unique identity record.
- Account Join - User accounts from access systems are allocated to the identity which holds the actual ownership of the accounts.
- Lookups - Data from other objects is looked up and can be added to the import flow. For example and email from an active directory can be added to the identity object.
- Delete Detection - Deleted records are detected and managed to not appear as active.
Below you can find different ES processing status values that are available in the GraphQL views.
| Value | Meaning |
|---|---|
| 0 | Unprocessed - no actions taken |
| 1 | Processed - successfully imported to the ES |
| 2 | RejectedByEs - error while importing to the ES |
| 3 | BeingProcessed - fetched from GraphQL, but not yet imported |
| 4 | ToBeRetried - some properties were missing while fetching. Will be fetched again. |
| 5 | Skipped - excluded by export queries and mapping filters |
| 6 | Ignored - entity coming from simulated import |
| 7 | Unchanged - entity imported with no changes compared to the existing entity in the ES |
| 8 | ThresholdViolated - entity processed but not imported to ES due to threshold violation |
| 9 | NoObjectToUpdate - object to update or delete is not found in the ES |
Delta processing
This feature allows to reduce the data import time. This is achieved by generating a hash for each record during import to determine if the record should be processed. If the data in the system undergoing an import was not altered, the hash is not updated and the record is not processed.
When the Reset source system high-water marks setting is enabled only full import in the staging is initiated.
Adapting
In this stage imported data that were processed in the IDS are shared with the Enterprise Server and Role and Policy Engine (RoPE), allowing to calculate identities affected by the data import.
Horizons import statuses
Depending on the results of each import stage the overall import status can be different.
Statuses
The table presents possible outcomes of the import.
| Staging | Processing | Adapting | Import Status | Import Profile - Status Text | ES - Import Status |
|---|---|---|---|---|---|
| ImportComplete | Import Succeeded | ||||
| ImportPartlyComplete | Import completed with warnings - please go to Import Progress page and the import logs for more details | ||||
| ImportPartlyComplete | Import completed with warnings - please go to Import Progress page and the import logs for more details | ||||
| ImportPartlyComplete | Import completed with warnings - please go to Import Progress page and the import logs for more details | ||||
| ImportPartlyComplete | Import completed with warnings - please go to Import Progress page and the import logs for more details | ||||
| ImportPartlyComplete | Import completed with warnings - please go to Import Progress page and the import logs for more details | ||||
| ImportPartlyComplete | Import completed with warnings - please go to Import Progress page and the import logs for more details | ||||
| ImportPartlyComplete | Import completed with warnings - please go to Import Progress page and the import logs for more details | ||||
| One or more systems fail (but not all) in Staging | – | – | ImportPartlyComplete | Import Failed - please go to Import Progress page and the import logs for more details | |
| – | – | Failed | Import Failed - please go to Import Progress page and the import logs for more details | ||
| – | – | Failed | Import Failed - please go to Import Progress page and the import logs for more details | ||
| All systems fail in Staging | – | – | Failed | Import Failed - please go to Import Progress page and the import logs for more details |